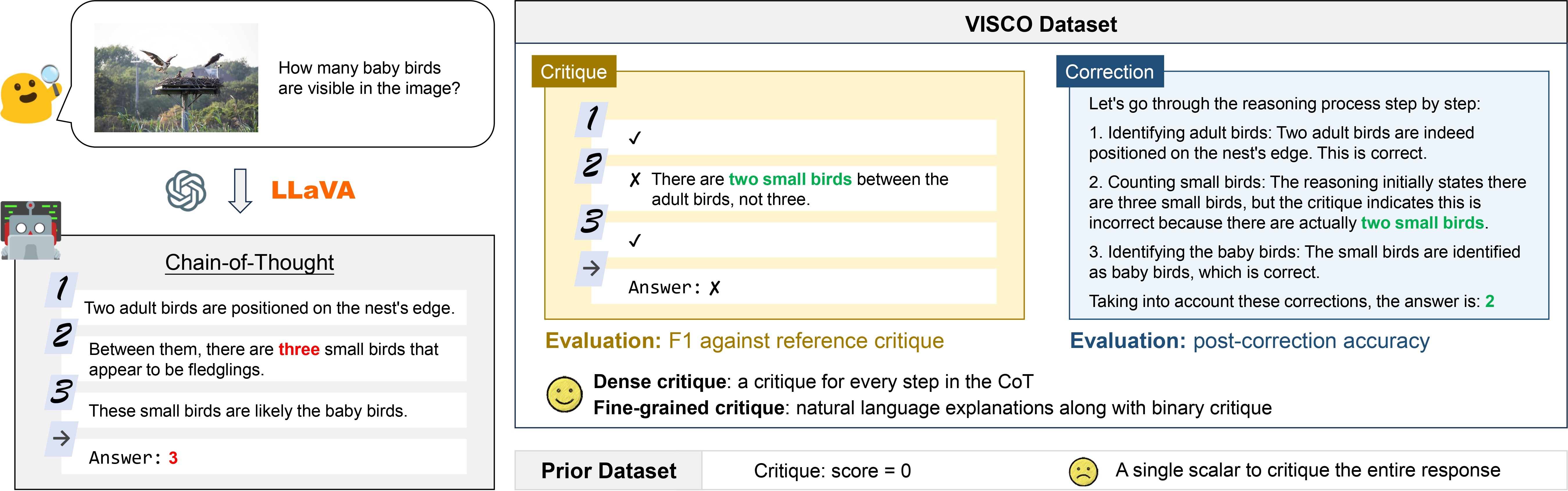
| # | Model | Source | Critique | Correction Gain | ||||
|---|---|---|---|---|---|---|---|---|
| VISCore🏅 | Ans. F1 | Step F1 | Ex. F1 | Human Critique | Model Critique | |||
| - | Human* | 86.47 | 100.0 | 90.6 | 71.4 | |||
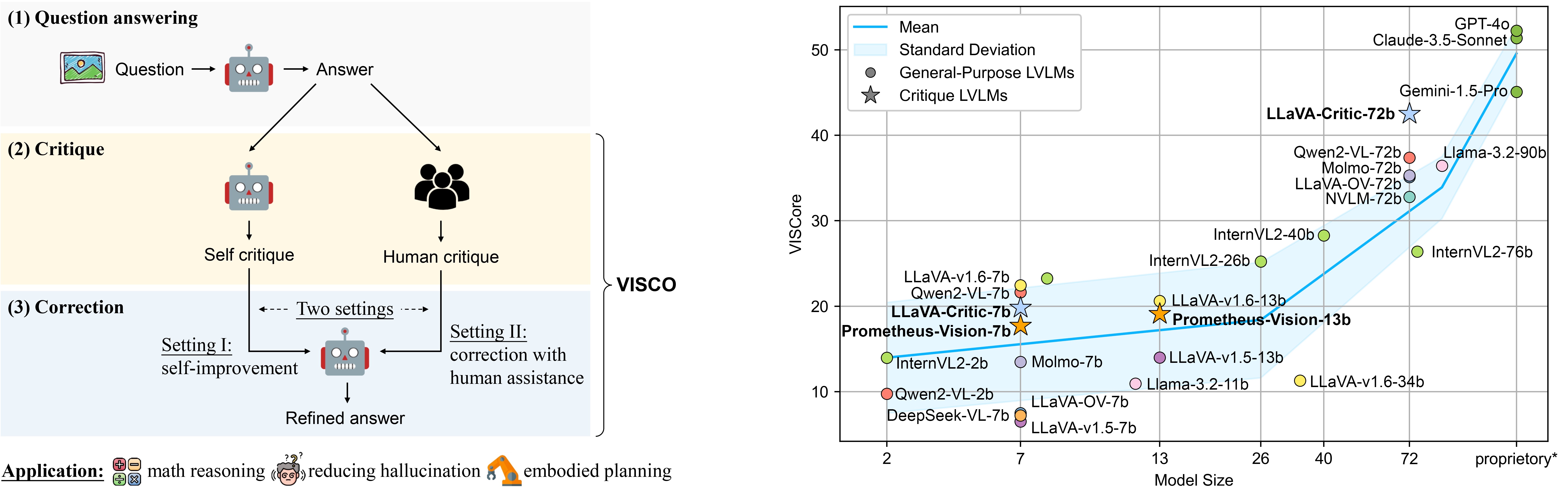
| 1 | Qwen2.5-VL-72B 🥇 | Link | 55.59 | 64.3 | 61.1 | 43.7 | 73.1 | 31.6 |
| 2 | GPT-4o-2024-08-06 🥈 | Link | 52.36 | 63.0 | 57.2 | 39.8 | 76.2 | 28.8 |
| 3 | Claude-3.5-Sonnet-20240620 🥉 | Link | 51.28 | 61.8 | 58.1 | 37.6 | 73.7 | 25.6 |
| 4 | Gemini-1.5-Pro | Link | 45.01 | 55.6 | 51.2 | 32.0 | 78.0 | 24.9 |
| 5 | LLaVA-Critic-72B | Link | 42.60 | 53.9 | 50.9 | 28.2 | 58.9 | 15.4 |
| 6 | Qwen2-VL-72B | Link | 37.44 | 49.2 | 41.9 | 25.5 | 31.5 | -2.1 |
| 7 | Llama-3.2-90B | Link | 36.40 | 46.8 | 42.5 | 24.3 | 66.4 | 4.4 |
| 8 | Molmo-72B | Link | 35.59 | 49.4 | 39.8 | 22.9 | 53.1 | 1.4 |
| 9 | LLaVA-OV-72B | Link | 35.27 | 47.1 | 42.0 | 22.2 | 33.4 | -10.2 |
| 10 | Qwen2.5-VL-7B | Link | 34.73 | 53.9 | 46.7 | 16.7 | 51.6 | 14.7 |
| 11 | NVLM-72B | Link | 33.07 | 44.0 | 38.6 | 21.3 | 42.2 | 1.7 |
| 12 | InternVL2-40B | Link | 28.48 | 41.6 | 31.4 | 17.7 | 47.6 | 9.9 |
| 13 | InternVL2-76B | Link | 26.38 | 37.7 | 28.6 | 17.0 | 72.7 | 11.7 |
| 14 | InternVL2-26B | Link | 25.20 | 39.4 | 30.2 | 13.4 | 59.3 | 6.0 |
| 15 | InternVL2-8B | Link | 23.33 | 37.1 | 31.1 | 11.0 | 52.7 | 5.4 |
| 16 | LLaVA-v1.6-7B | Link | 21.80 | 44.6 | 33.6 | 6.9 | 40.3 | -8.7 |
| 17 | Qwen2-VL-7B | Link | 21.71 | 43.0 | 30.6 | 7.8 | 50.8 | 5.5 |
| 18 | LLaVA-v1.6-13B | Link | 21.02 | 40.2 | 32.8 | 7.1 | 40.2 | -7.2 |
| 19 | LLaVA-Critic-7B | Link | 20.02 | 32.0 | 28.7 | 8.8 | 19.3 | -11.4 |
| 20 | Prometheus-Vision-13B | Link | 19.32 | 38.0 | 37.8 | 5.0 | -† | -† |
| 21 | Prometheus-Vision-7B | Link | 17.67 | 37.6 | 35.8 | 4.1 | -† | -† |
| 22 | Molmo-7B | Link | 13.43 | 35.5 | 22.0 | 3.1 | 49.1 | 1.8 |
| 23 | MiniCPM-V-2.6 | Link | 13.07 | 27.9 | 18.2 | 4.4 | 53.0 | 7.8 |
| 24 | Llama-3.2-11B | Link | 11.44 | 29.4 | 21.1 | 2.4 | 34.8 | -11.7 |
| 25 | LLaVA-v1.6-34B | Link | 11.05 | 23.6 | 14.3 | 4.0 | 39.2 | -1.7 |
| 26 | LLaVA-OV-7B | Link | 7.53 | 14.5 | 14.9 | 2.0 | 22.4 | -9.1 |
| 27 | DeepSeek-VL-7B | Link | 7.53 | 21.8 | 15.7 | 1.2 | 2.3 | -17.9 |
| - | Random | - | 37.9 | 32.0 | - | |||
Negative correction gain : Correction brings more harm than benefits to task performance.
No correction results † : After specialized training, Prometheus-Vision models lack general question answering capability and cannot perform correction.
🚨 To submit your results to the leaderboard, please send to this email with your result json files.














